Le moteur HFSQL Client/Serveur dispose de mécanismes de "log" et de suivi d'activité. Ils permettent d'avoir très précisément sur une période donnée, toutes les actions commandées par les différentes utilisateurs connectés aux bases de données.
Il est donc vivement recommandé d'activer ces mécanismes sur le serveur :
ils n'ont pas d'incidence notable sur les performances,
il suffit pour les activer de se connecter au serveur via le centre de contrôle HFSQL :
Une fois l'activation faite, il suffit toujours dans le centre de contrôle HFSQL d'utiliser le volet "Logs et Statistiques" pour accéder à de nombreuses informations primordiales notamment en phase de mise au point, et d'optimisation :
les requêtes les plus longues,
les appels les plus longs,
les requêtes les plus utilisées (pour optimiser en priorité les traitements les plus courants),
la liste des commandes appelées (par exemple vérifier les paramètres reçus par une requête d'un utilisateur qui n'a pas le résultat attendu),
...
L'ensemble de ces possibilités permet de répondre à toutes les interrogations pouvant survenir en exploitation :
le dimensionnement du réseau est-il suffisant ? Les statistiques d'activités montrent le volume des demandes.
le dimensionnement du serveur est-il suffisant ? Les statistiques d'activités montrent l'utilisation de la RAM et du CPU sur le serveur.
un résultat ne semble pas conforme ? Les logs permettent de vérifier les demandes reçues.
un arrêt inattendu du moteur survient, ou une erreur du journal des événements de Windows remonte ? Les logs permettent de voir la demande, ou l'enchainement de traitements à l'origine.
Ces possibilités de suivi s'appliquent pour toutes les connexions gérées par le moteur HFSQL Client/Serveur, qu'elles proviennent des stations du réseau local, de postes connectés par Internet, d'applications mobiles Android, iOS...
Important : pour tous les serveurs de données il est important d'ajuster l'usage des caches du système afin de ne pas manquer de mémoire.
L'ouverture d'un fichier de données au niveau du système d'exploitation est coûteuse en temps. En effet, le système doit mettre en place bon nombre de mécanismes pour assurer par la suite les entrées/sorties (allocation, partage réseau, cache ...).
Pour optimiser le lancement des applications, il est donc déconseillé d'effectuer une ouverture systématique de tous les fichiers en appelant l'une des fonctions suivantes :
HOuvre("*") HCréationSiInexistant("*")
Pour cela le moteur HFSQL est doté d'un mécanisme d'ouverture automatique des fichiers. Il permet dès le premier accès à un fichier, d'effectuer son ouverture si elle n'a pas déjà été faite. Le temps nécessaire aux ouvertures des fichiers est ainsi réparti tout au long de l'application, plutôt qu'en une seule fois au lancement. La fonction HPasse permet si besoin de spécifier le mot de passe des fichiers pour le mécanisme d'ouverture automatique. Le gain peut être de plusieurs secondes dans une applications ayant des centaines de fichier.
Autre avantage de ce mécanisme, seuls les fichiers effectivement utilisés sont ouverts, limitant ainsi les ressources nécessaires sur le serveur de données.
Ce mécanisme d'ouverture automatique est disponible pour HFSQL Client/Serveur mais également pour HFSQL Classic.
Astuce : Il est recommandé de cocher l'option suivante dans le projet, afin de s'assurer d'avoir en plus de l'ouverture automatique des fichiers, leur création automatique :
menu "Projet ... Description duprojet",
volet "Fichiers",
cocher "Créer automatiquementles fichiers de données".
Cette solution évite de conserver dans le programme l'appel suivant, pour les prochains ajouts de fichiers de données dans la base :
Lorsque le moteur HFSQL Client/Serveur est installé sur un serveur Linux, l'accès à un fichier (lecture, exécution d'une requête, ouverture de fichier, sauvegarde ...) peut se solder par le retour "too many open file" remonté par le mécanisme de sécurité HFSQL.
En effet, contrairement à un serveur sous Windows un serveur Linux est par défaut limité en nombre de "handles" pouvant être alloués pour tous les fichiers ouverts.
Les réglages à apporter au serveur afin d'augmenter le nombre de handles disponibles sont décrits dans la FAQ 4345.
Se pose donc la question de l'évaluation du nombre de handles nécessaires pour éviter ce retour "too many open file". Il dépend de chaque application, du nombre de fichiers, du nombre de bases de données :
1 handle par fichier physique (.fic, .ndx, .mmo, .ftx), donc jusqu'à 4 par fichier logique décrit dans l'analyse,
7 handles par bases de données,
1 handle par client connecté par base de données,
50 handles pour la gestions interne du moteur HFSQL Client/Serveur.
Par exemple un serveur avec deux bases, une base avec 900 fichiers et une base avec 50 fichiers, avec une moyenne de 150 utilisateurs connectés simultanément aux deux bases :
700x2+150x3+50x4 : base de 900 fichiers, 700 données et index, 150 avec mémo en plus, 50 avec mémo et index full-text
40x2+10x3 : base de 50 fichiers : 40 sans mémos et 10 avec mémos
7 x 2 : handles pour chaque base
150 x 2 : handles pour chaque utilisateur sur chaque base
50 : handles pour la gestion interne
1400+450+200+80+30+14+300+50 = 2524 handles sont donc nécessaires pour le serveur HFSQL.
Il faut donc au minimum 2524 handle pour l'utilisateur Linux qui exécute le service (deamon) "manta" (root par défaut). Il faut ajouter à ce nombre les handle qui seront nécessaires à cet utilisateur pour effectuer d'autres opérations sans rapport avec HFSQL, à déterminer en fonction des autres tâches du serveur Linux.
Voici quelques commandes Linux utiles sur ce sujet :
Connaître le nombre de handles d'un processus à un moment donné : lister : ls -l /proc/<pid>/fd/* compter : ls -l /proc/<pid>/fd/* | wc -l (dans cette ligne le dernier paramètre est la lettre "L" en minuscule) <pid> étant le numéro de pid du process dont on veut la liste des handles
Connaître le PID d'un processus (manta) : ps -ef | grep manta
Lorsqu'une application utilisant des données HFSQL est déployée, il est à tout moment possible de faire évoluer la structure de ses données :
ajouts / suppressions de rubriques,
modifications du type ou de la taille de rubriques,
ajouts de clés uniques ou avec doublons,
ajouts d'index full-text...
Cette évolution se fait grâce à la modification automatique des fichiers de données. Elle permet de conserver les enregistrements déjà créés dans les fichiers de données, qu'ils soient exploités avec HFSQL Client/Serveur ou Classic, sans avoir à programmer une "moulinette" de mise à jour, ou à exécuter des requêtes SQL spécifiques de type "alter table".
Le traitement de modification automatique des données se base sur un principe simple de "GUID" : lors de l'ajout d'une description de fichier dans l'éditeur d'analyses, un "GUID" unique lui est attribué. Ce "GUID" est visible dans le volet "Notes" de la description de chaque fichier. De la même manière, à chaque création d'une rubrique dans la description d'un fichier, un "GUID" unique lui est attribué. Ce "GUID" de rubrique est visible dans le volet "Avancé" de la description de chaque rubrique.
En exploitation, lors de la création physique d'un fichier de données par les fonctions HFSQL Hcréation ou HcréationSiInexistant à partir de l'application compilée, les GUID du fichier et de toutes ses rubriques sont inscrits dans le fichier de données physiques ".FIC".
Le traitement de modification automatique d'un fichier de données consiste donc à consulter l'ensemble des GUID des rubriques dans la description du fichier inclus dans un nouvel exécutable, afin de les comparer à ceux présents dans le fichier de données physique :
si le GUID d'une rubrique est présent dans la description du fichier de la nouvelle analyse, mais absent du fichier de données, il s'agit d'une nouvelle rubrique ajoutée par le développeur. La modification automatique va donc ajouter au fichier de données la rubrique, en l'initialisant pour chaque enregistrement à sa valeur par défaut.
si le GUID d'une rubrique est présent dans la description du fichier dans l'analyse, et dans le fichier de données, il s'agit d'une rubrique existante. La modification automatique va donc vérifier le type et la taille de la rubrique, afin de l'ajuster si besoin.
enfin si des rubriques du fichier de données ont des GUID qui n'existent pas dans la description du fichier dans l'analyse, il y a donc eu des suppressions de rubriques dans l'analyse, la modification automatique des fichiers de données supprime les rubriques devenues obsolètes.
Liens utiles sur ce thème :
fonction HModifieStructure : pour gérer la mise à jour des données depuis une application,
fonction HvérifieStructure : pour autoriser la lecture d'un fichier en cas de déphasage de sa description physique avec celle de l'analyse,
WDMODFIC : utilitaire interactif ou piloté en ligne de commande pour la modification des données,
Important :
en cas de suppression par erreur d'une rubrique dans l'analyse, il est important de bien restaurer la rubrique, il ne faut pas en recréer une nouvelle : En effet par la création d'une nouvelle rubrique le mécanisme de modification automatique des données serait induit en erreur, son rôle serait alors de supprimer le contenu initial de la rubrique, afin d'en créer une nouvelle.
lorsque plusieurs versions d'une application existent dans des branches du GDS, il ne faut pas créer des rubriques dans les différentes versions de l'analyse contenues dans les branches.
Le moteur HFSQL utilise un principe de statistiques sur les clés définies dans les fichiers de données.
Ces statistiques sont systématiquement utilisées que l'exploitation soit faite avec HFSQL Classic ou HFSQL Client/Serveur, dès qu'une application va :
effectuer des lectures en filtrant les données (HFiltre, POUR TOUT...),
interroger la base via une requête,
créer une vue ...
Les statistiques permettent en effet au moteur de déterminer les rubriques les plus discriminantes qui permettront d'optimiser les parcours et sélection de données.
Il est donc capital de maintenir à jour les statistiques des index, notamment lorsque les données subissent des mouvements importants.
La mise à jour des statistiques peut être faite à différents niveaux :
directement dans une application avec la fonction HstatCalcule.
via une tâche planifiée du moteur HFSQL Client/Serveur, par exemple pour un traitement lorsque l'application n'est pas utilisée.
lors de la réindexation de la base de données.
Il est important d'insister sur l'aspect fondamental de ces statistiques sur les performances. Lorsqu'il y a eu de nombreuses opérations de mises à jour des données (ajouts, modifications suppressions), le classement des index peut ne pas être suffisamment favorable pour obtenir les meilleures performances. Dans ce cas le simple recalcule des statistiques peut réduire les temps d'exécution par un facteur allant de 2 à 10, voir beaucoup plus dans les cas les plus défavorables.
Quelque soit la méthode retenue afin de garder les statistiques à jour, il est conseillé d'ajouter dans les applications une vérification de la date du dernier calcul (cf. fonction HStatDate). L'application peut ainsi faire remonter l'information à l'utilisateur, l'administrateur, le développeur suivant le cas, dès que les statistiques ne sont plus suffisamment à jours.
Les bases de données utilisées par WINDEV, WEBDEV et WINDEV Mobile sont également concernées par les statistiques, notamment le GDS. Typiquement après des modifications importantes comme l'ajout de branches, ou de projets, un recalcule des statistiques de la base du GDS, via son option de réindexation, peut réduire considérablement les temps d'accès.
Lors du remplacement physique d'un serveur de données, une fois l'installation du moteur HFSQL Client/Serveur faite, il faut récupérer les données du serveur précédent. De la même manière, pour l'installation d'un serveur de tests à partir d'un serveur de production existant, il faut pouvoir récupérer l'intégralité du serveur en exploitation :
toutes les bases de données,
les groupes et utilisateurs,
la configuration des droits...
La solution permettant de dupliquer un serveur complet est dépendante des possibilités d'accès aux serveurs :
Premier cas : en ayant un accès complet aux serveurs (Bureau à distance, VNC, partage réseau..,), un simple copier/coller est suffisant :
via le centre de contrôle HFSQL arrêt du serveur existant qui contient les données,
via le centre de contrôle HFSQL arrêt du moteur HFSQL Client/Serveur sur le nouveau serveur de données,
via l'explorateur copie de tout le dossier des données du serveur "source" (\BDD\ par défaut), en incluant tous les dossiers et fichiers cachés. La copie se fait vers le dossier des bases du nouveau serveur (\BDD par défaut). Elle peut se faire en direct via le réseau, par l'intermédiaire d'un disque USB...
une fois la copie terminée, via le centre de contrôle HFSQL redémarrage du nouveau serveur qui dispose alors de toutes les données du serveur initial.
Second cas : sans accès via l'Explorateur à l'emplacement des données physiques du nouveau serveur. Il faut dans ce cas travailler via une connexion HFSQL au serveur.
1. Soit avec le centre de contrôle HFSQL :
connexion au serveur,
volet "Sauvegarde",
sauvegarder "Tout le contenu du serveur" à chaud, sous la forme d'un fichier ZIP
transférer le zip contenant la sauvegarde intégrale sur le nouveau serveur,
restaurer la sauvegarde via le centre de contrôle HFSQL, connecté au nouveau serveur HFSQL.
2 Soit avec l'utilitaire proposé dans la LST 89 : WD DupliqueServeur. Cet utilitaire permet une duplication complète en passant toutes les données via le port d'accès au nouveau serveur. L'utilitaire se charge des transferts suivants :
bases de données / Fichiers HFSQL,
liaisons,
paramètres (spécifiques à chaque base de données),
L'utilisation des différents processeurs, ou des différents coeurs du ou des processeurs, et gérée automatiquement par le système d'exploitation, et le moteur HFSQL Client/Serveur. Aucune programmation particulière n'est requise, le traitement parallèle des requêtes est systématique.
En effet pour chaque interrogation par une application cliente, le moteur HFSQL Client/Serveur (manta.exe) utilise un thread. Exemples :
un poste client exécute la fonction d'ajout d'un enregistrement HAjoute sur un fichier : lancement d'un thread sur le serveur,
un poste client exécute une requête SQL : son exécution est faite dans un nouveau thread sur le serveur,
un poste client lance un ajout dans un fichier, et un parcours d'une requête, là également deux threads seront lancés sur le serveur.
C'est ensuite le système d'exploitation qui se charge de la répartition des différents threads lancés, sur les différents processeurs présents, et/ou les différents coeurs des processeurs.
En synthèse, pour la machine physique hébergeant le moteur HFSQL Client/Serveur, la multiplication des coeurs est vivement conseillée :
c'est transparent pour le développement,
toutes les applications disposent ainsi de meilleurs temps de réponse.
Sur le thème de la configuration d'un serveur de données, la page suivante contient un descriptif détaillé :
Lors de la création d'une réplication entre deux serveurs HFSQL client/serveur, l'assistant du centre de contrôle HFSQL propose une copie initiale des fichiers à répliquer :
Grâce à cette option, une fois l'assistant validé, il y a une initialisation intégrale de la nouvelle réplication :
ajout et configuration de la réplication sur les deux serveurs,
création sur le nouveau serveur cible de la réplication des nouvelles données strictement identiques à celle du serveur "maître".
Les deux bases sont ainsi synchronisées, la réplication monodirectionnelle ou bidirectionnelle est immédiatement active en continu (streaming), ou suivant la périodicité donnée.
Cette solution la plus simple et immédiate peut ne pas être appropriée lorsque la base à répliquer fait plusieurs dizaines de gigas, et que le débit de la connexion via TCP/IP entre les serveurs ne permet pas un transfert suffisamment rapide de l'ensemble des données pour la synchronisation initiale. Dans ce cas, il est possible d'effectuer un transfert des données par un support physique, ou tout autre moyen d'échange disponible entre sur le site.
Voici le mode opératoire détaillé, en utilisant "maître" pour nommer le serveur qui dispose des données de départ, et "abonné" pour désigner le serveur qui va recevoir les nouvelles données du "maître". Ce mode opératoire s'applique pour toutes les possibilités de configuration de la réplication (monodirectionnel, bidirectionnelle, continue, ...) :
effectuer sur le maître un blocage préalable des applications qui utilisent les données à répliquer,
effectuer sur le maître une copie complète des données de la base de données à répliquer (dossier \BDD\<NomBase>\), il est également possible de ne copier que certains fichiers d'une base si la réplication ne doit s'appliquer qu'à certains fichiers,
se connecter au serveur HFSQL client/serveur "maître" via le centre de contrôle HFSQL,
lancer l'assistant de création de la réplication via le volet "Configuration",
via le centre de contrôle HFSQL se connecter au serveur abonné et l'arrêter à son tour,
sur le serveur abonné, via l'Explorateur de Windows, remplacer le dossier \BDD\<NomBase>\ qui a été initialisé à vide par l'assistant de création de la configuration, par les données copiées sur le serveur "maître" (étape 2 ci-dessus). De cette manière les deux serveurs ont leurs données strictement identiques, comme si la copie avait été faite avec l'option "Effectuer la copie initiale ...",
via le centre de contrôle HFSQL redémarrer les serveurs HFSQL.
Les deux serveurs HFSQL ont maintenant les mêmes données, la réplication est initialisée et la synchronisation effectuées.
Le moteur HFSQL propose en version 19 différents modes d'isolation des transactions. Ils permettent de configurer finement les mises à jour des données partagées entre différentes applications et sites Web.
Il s'agit des nouveautés 140 à 147 de la version 19, leur documentation complète vient d'être mise en ligne :
Toutes les applications et sites qui utilisent des données d'une base HFSQL client/serveur, reposent sur une connexion permanente entre l'application, ou le site, et le moteur HFSQL client/serveur. Cette connexion repose sur le protocole TCP/IP, et l'utilisation de sockets.
Pas d'exception pour confirmer la règle, qu'il s'agisse :
d'une application WINDEV sous Windows 32 ou 64 bits,
d'un site WEBDEV,
d'une application mobile sous iOS ou Android compilée avec WINDEV Mobile,
d'un moteur HFSQL client/serveur installé sur un réseau local, distant, ou dans un CLOUD (PCSCLOUD, ...),
c'est toujours une connexion TCP qui servira à l'envoi des requêtes au moteur HFSQL client/serveur, à la récupération des données...
Le but de ce billet est de détailler comment sont faites les connexions, puis surtout les déconnexions. En effet comme toujours, lorsque l'on connaît le principe de fonctionnement, il devient plus simple de déterminer les solutions à mettre en place, quelque soit le but à atteindre !
ou implicitement dès qu'il sera nécessaire d'interroger le serveur, car toutes les fonctions HFSQL (H*), ouvrent si besoin la connexion associée aux tables. C'est valable pour les connexions décrites dans l'analyse, mais également par programmation, ou paramétrées lors du déploiement de l'application.
Dans les deux cas le centre de contrôle HFSQL (CCHF) permet de visualiser les connexions ouvertes par les applications, via le volet "Connexions". C'est un autre sujet, mais soulignons qu'un même processus peut instancier plusieurs clients HFSQL et donc ouvrir plusieurs connexions, grâce aux contextes HFSQL indépendants (disponible également pour les classes).
Voici maintenant les différents cas possibles qui vont terminer les connexions :
L'application n'a plus besoin des données du serveur et poursuit son exécution dans une phase n'utilisant pas de donnée. Elle peut terminer ses connexions par un appel de la fonction HFermeConnexion. Elle libère ainsi sur le serveur les ressources nécessaires aux différentes connexions ouvertes.
L'application est terminée par son utilisateur par son option standard de fermeturen sans faire appel à HFermeConnexion. Toutes les connexions ouvertes par le processus sont automatiquement fermées. En effet dans ce cas l'arrêt du processus déclenche le déchargement des modules du framework, dont le client HFSQL fait partie. Le client HFSQL informe le serveur de l'arrêt du processus et, le moteur HFSQL peut donc supprimer les connexions.
L'application est terminée par un arrêt du processus (fin de tâche sur le processus). Dans ce cas le client HFSQL n'est pas déchargé, il ne peut donc envoyer au moteur HFSQL client/serveur la demande de fermeture des connexions en cours. Dans ce cas, c'est une fonctionnalité du système d'exploitation qui prend le relais. En effet, il gère automatiquement l'envoi d'un paquet réseau spécifique (RST) pour les connexions TCP de l'application. Le moteur HFSQL client/serveur gère la récupération de ces paquets, ainsi il peut mettre fin aux connexions même s'il n'a pas été notifié de façon standard par l'application.
Dans ces 3 cas, le moteur HFSQL client/serveur est notifié de l'arrêt de l'application et toutes les connexions sont immédiatement supprimées.
L'application n'est pas terminée, mais la connexion réseau est perdue. Pour le moteur HFSQL client/serveur la connexion est donc toujours présente, puisque ni l'application, ni le système client n'a pu le notifier (cas 1 2 3). Dans ce cas la connexion va persister sur le serveur, jusqu'à :
- la reconnexion automatique ou programmée de l'application qui était connectée, si la coupure de connexion n'a été que temporaire, et qu'il n'y avait aucune donnée bloquée (Cf. Limites de la fonction HReconnecte),
- un envoi d'information du moteur HFSQL client/serveur à cette connexion, par exemple un message, dans ce cas le serveur pourra détecter la connexion rompu et la supprimer,
- la réception d'une notification du système d'exploitation serveur sur le fait que la connexion TCP n'existe plus. En effet, les systèmes serveurs notifient régulièrement les processus qui communiquent via TCP/IP, dont le moteur HFSQL client/serveur, afin de leur signaler les éventuelles connexions qui ne sont plus valides. Dans ce cas le temps nécessaire pour que le moteur HFSQL client/serveur supprime la connexion est très variable, la fréquence de notification par le système étant réglable sur les serveurs (généralement aux alentours de deux heures).
Découlent de ces mécanismes un ensemble de constats, astuces...
En premier, pas d'inquiétude en cas d'une simple micro-coupure sur la connexion. En effet, puisque le moteur HFSQL client/serveur garde les connexions, les applications vont poursuivre leur exécution dès que la connexion sera restaurée (tant que le processus n'est pas arrêté). Voici les liens utiles en complément sur ce thème :
Ensuite dans le cas général la gestion des connexions ne nécessite aucune programmation spécifique, puisque même si la déconnexion n'est pas explicitement faite par l'application, le système permettra au moteur HFSQL de terminer une connexion inutile à plus ou moins court terme.
Enfin, on peut noter l'importance du fait que le moteur HFSQL client/serveur peut de lui-même supprimer une connexion perdue, si la communication vers l'application client liée à la connexion n'est plus joignable. En effet, si l'application qui a perdu la connexion vers le serveur a bloqué des enregistrements de la base de données, par défaut les données restent bloquées tant que le système serveur n'a pas notifié le moteur HFSQL client/serveur. Si une transaction était en cours, elle reste également active. Suivant le domaine d'activité, un déblocage plus rapide peut être souhaité. On peut donc l'obtenir en jouant sur le fait que le moteur HFSQL client/serveur supprime les connexions inexistantes, s'il tente l'envoi d'un message vers l'une de ces connexions. Pour forcer une communication du moteur HFSQL client/serveur vers les processus clients, dans le cas général toutes les communications sont à l'initiative des applications clientes, on peut utiliser la fonction HEnvoieMessageVersClient.
L'utilisation de cette solution avec HEnvoieMessageVersClient doit être prévue dans l'application, sous peine d'afficher des messages sur les postes de tous les utilisateurs de l'application, y compris ceux qui n'ont jamais été déconnectés ! La fonction HSurAppelServeur doit être appelée par les applications afin de personnaliser la gestion de l'affichage des messages, justement pour ne rien afficher ! Exemple de procédure (bien pratique) de réponse à HSurAppelServeur :
CAS"##RAS" // On ne fait strictement rien // message destiné à forcer le moteur HFSQL // à solliciter ses connexions pour les vérifier
CAS"##AZE" // Au passage on peut inventer toutes sortes de commandes // pour faire faire des actions aux applications à la demande // sans solliciter ni déranger l'utilisateur ! ExécuteTraitement(...) ThreadExecute(...)
AUTRES CAS: // Véritable message à afficher ! ToastAffiche(sMessageAAfficher,toastLong,cvMilieu,toastLong,VertPastel)
FIN
FIN
On note au passage que cette méthode peut permettre de commander à distance des actions aux applications ! Dans certains cas et du moment que toutes les applications partagent leur données via un même serveur HFSQL client/serveur, cela remplace avantageusement une solution du dialogue par socket ou messages Windows. D'autant plus que la structure HClient permet de gérer finement l'envoi des messages. Un exemple d'utilisation de HEnvoieMessageVersClient a été proposé dans la LST 90 p30 : WD Notification.
La majeure partie des applications qui utilisent HFSQL accèdent maintenant aux données via le moteur HFSQL client/serveur. L'utilisation d'accès par une technologie client/serveur est en effet très vivement recommandée par rapport à un accès en partage.
Pour les applications qui utilisent encore un accès direct aux données HFSQL (HFSQL classic – ISAM), dans le cas général les données sont stockées dans un emplacement sécurisé modifiable, disque local ou partage réseau, afin de permettre l'enregistrement d'informations.
Mais il est également possible d'inclure des données HFSQL classic directement dans la bibliothèque (WDL) d'un exécutable, lorsque l'on souhaite proposer des données figées en consultation seulement.
Peu d'applications utilisent ce mécanisme puisque généralement les données sont modifiables. Ce billet le détaille cependant, car toutes les applications sont impactées par ce mécanisme. En effet, afin de permettre l'utilisation de données HFSQL classic intégrées à un exécutable, lors de l'accès à un fichier il y a d'abord sa recherche dans l'exécutable. Si cette recherche ne trouve les données HFSQL intégrées, alors les donnée sont utilisées le disque à l'emplacement spécifié par HChangeRep.
De ce mécanisme découlent deux optimisations importantes pour toutes les applications qui exploitent traditionnellement les données sur disque :
la principale concerne la recherche des fichiers de données dans l'exécutable. En fonction du nombre d'éléments du projet, la recherche des fichiers de données peut être coûteuse en temps. Il est donc possible d'indiquer à HFSQL classic qu'il ne doit pas rechercher les fichiers HFSQL dans l'exécutable, grâce à la fonction HChangeLocalisation :
// Ouverture du projet, avant l'accès aux données : HChangeLocalisation("*",hDisque).
Le gain n'est pas significatif pour les projets ayant une centaine d'éléments. Il devient très intéressant dès que le projet a au moins 1000 éléments.
la seconde optimisation concerne la conservation de la localisation des données utilisées via le fichier .REP. Dans le cas d'une application utilisant plusieurs jeux de données, l'accroissement progressif de la taille du .REP peut impacter les temps d'accès. Il est donc possible d'optimiser les accès en supprimant régulièrement du .REP les emplacements obsolètes, et/ou en inhibant sa gestion par HGèreRep lorsque c'est possible.
France Métropolitaine : les envois seront expédiés à partir du 25 janvier en courrier "Fréquence". Les livraisons sont prévues semaines 6 et 7.
DOM-TOM et Etranger : les envois seront expédiés le 1er février en Courrier Postal Prioritaire. Les livraisons sont prévues semaines 7 et 8 selon les destinations.
Le “Goodies du trimestre” est un luxueux calendrier mural qui vous accompagnera tout au long de l'année 2016 !
Un nouveau Webinaire est programmé jeudi 28 janvier à 11h.
Dans cette session de 20 minutes, vous découvrirez comment donner plus de mobilité à la force de vente. Pour cela, nous allons créer un tableau de prise de commande pour une application tablette (Android ou iPad).
Le principe est le même pour la réalisation de devis.
Après la diffusion en directe, la vidéo restera disponible avec ce même lien.
35 sujets / 3h45 de formation / 11 villes 100% Technique, 100% Productif, 100% Gratuit de 13H45 à 17H30
Attention: 10.000 places seulement disponibles
Parmi les 35 sujets techniques : Les nouveaux champs 21, le cloud, porter une application de WINDEV à WINDEV Mobile et à WEBDEV, comment améliorer la vitesse de vos requêtes, les nouveautés de l'environnement 21, les nouveautés du WLangage, le Responsive, les nouveautés en mobile...
Un nouveau Webinaire est programmé jeudi 11 février à 11h.
Dans cette session de 20 minutes, vous découvrirez comment créer un serveur REST (REST API) d'accès à vos données. Ce jeu d'API pourra être utilisé depuis tout client HTTP (desktop, web, mobile).
Après la diffusion en directe, la vidéo restera disponible avec ce même lien.
Retrouvez l'ensemble des webinaires sur notre site :
Cette version n'a pas encore subi le deuxième niveau de validation par le Service Qualité. Vous pouvez trouver une information complète sur les niveaux de validation sur notre site :
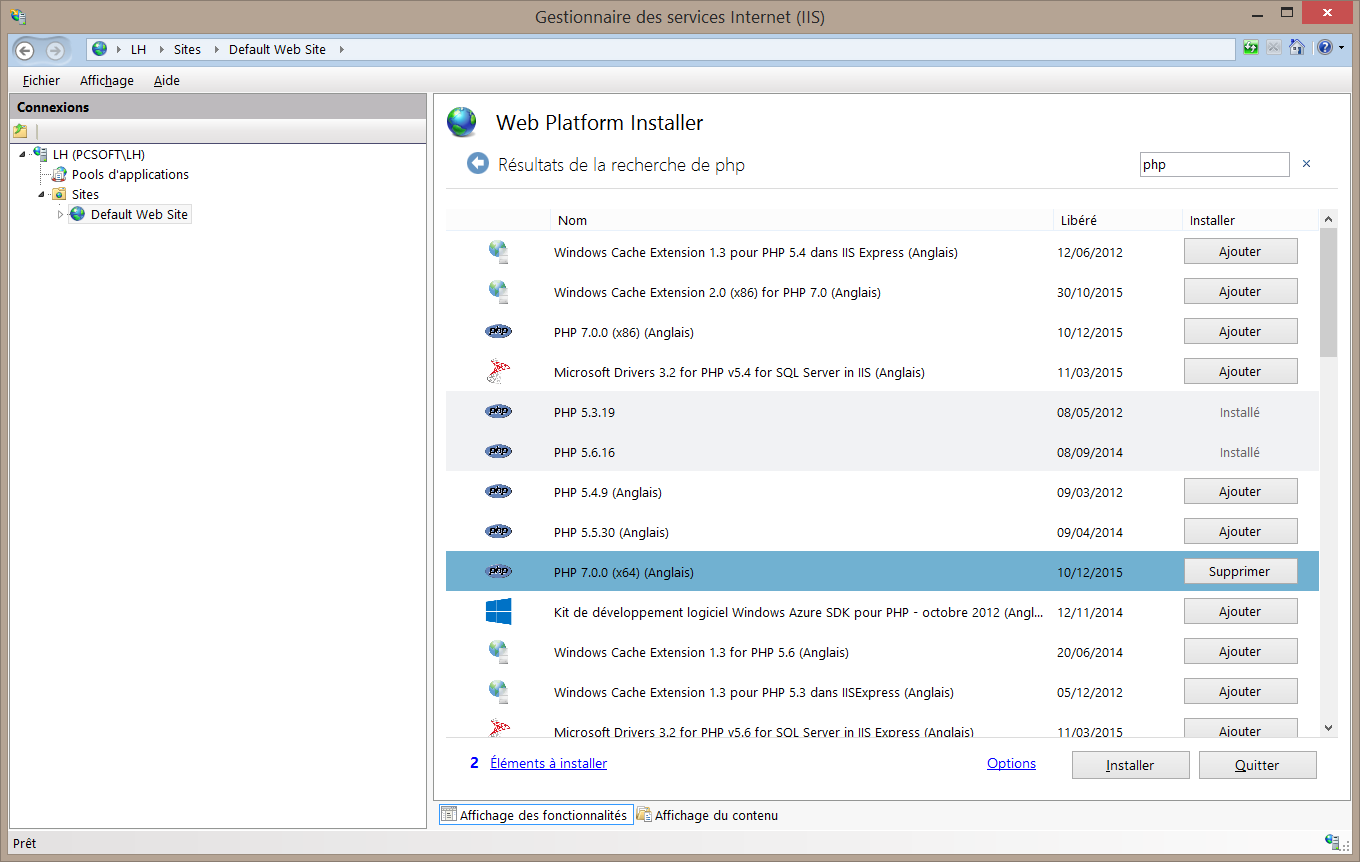
Pour tester les sites PHP que vous développez avec WEBDEV, il est nécessaire d'installer un moteur PHP sur votre poste de développement. On trouve sur Internet de nombreux packages d'installation du moteur PHP mais ces packs sont très souvent couplés à une installation du serveur web Apache. Si vous utilisez déjà le serveur web par défaut de votre poste (IIS), le changer implique reprendre la configuration pour WEBDEV et vos autres développements.
Vous trouvez ici une méthode d'installation d'un moteur PHP pour IIS. Cette méthode utilise le module " Web Platform Installer ".
Installation de " Microsoft Web Platform Installer " :
Une fois installé, cet outil est accessible directement depuis la console de Microsoft IIS (démarrer...exécuter...inetmgr). Pour le lancer, il suffit de double cliquer dessus.
Utilisation de " Microsoft Web Platform Installer " :
Lancez cet outil, choisissez le volet Produits. " Web Platform Installer " vous propose toute une liste d'outils disponible pour la gestion de votre site Web et compatibles avec IIS (Moteur PHP, Pilotes ODBC, SDK divers, etc...).
Je vous conseille d'utiliser le champ de recherche. Saisissez php et validez, la liste se réduit aux outils concernant PHP.
Choisissez la version du moteur PHP que vous souhaitez installer et cliquez sur le bouton Ajouter. " Web Platform Installer " sélectionne automatiquement les modules complémentaires obligatoires selon la version de IIS que vous utilisez et vous indique le nombre de modules à installer.
Il suffit ensuite de cliquer sur Installer pour lancer l'installation.
" Web Platform Installer " va télécharger le moteur PHP, lancer l'installation et ce qui est particulièrement intéressant, va configurer le serveur IIS pour ce moteur.
Une fois cette installation réalisée, vous pourrez tester directement vos sites PHP réalisés avec WEBDEV sur votre poste de développement par un simple GO de la même manière que pour vos sites WEBDEV.
Des nouveautés des versions 21 viennent d'être détaillées dans la documentation en ligne :
WEBDEV - Responsive Web Design : nouvelles pages, et différentes mises à jour avec la mise à disposition des modèles notamment à partir de la version 210051f. Il est vivement recommandé de consulter les pages dans cet ordre afin de découvrir la fonctionnalité :